Games Samsung’s Flagship Galaxy Tablets & Earbuds Are On Sale For New Low Prices 2025-07-12 Read More
Games Viture Pro XR Glasses Prime Day Deal: Save Big On Wearable 135-Inch Display 2025-07-11 Read More
Games EA Japan GM Criticizes Microsoft Layoffs And Cancellations As Harmful To The Industry 2025-07-10 Read More
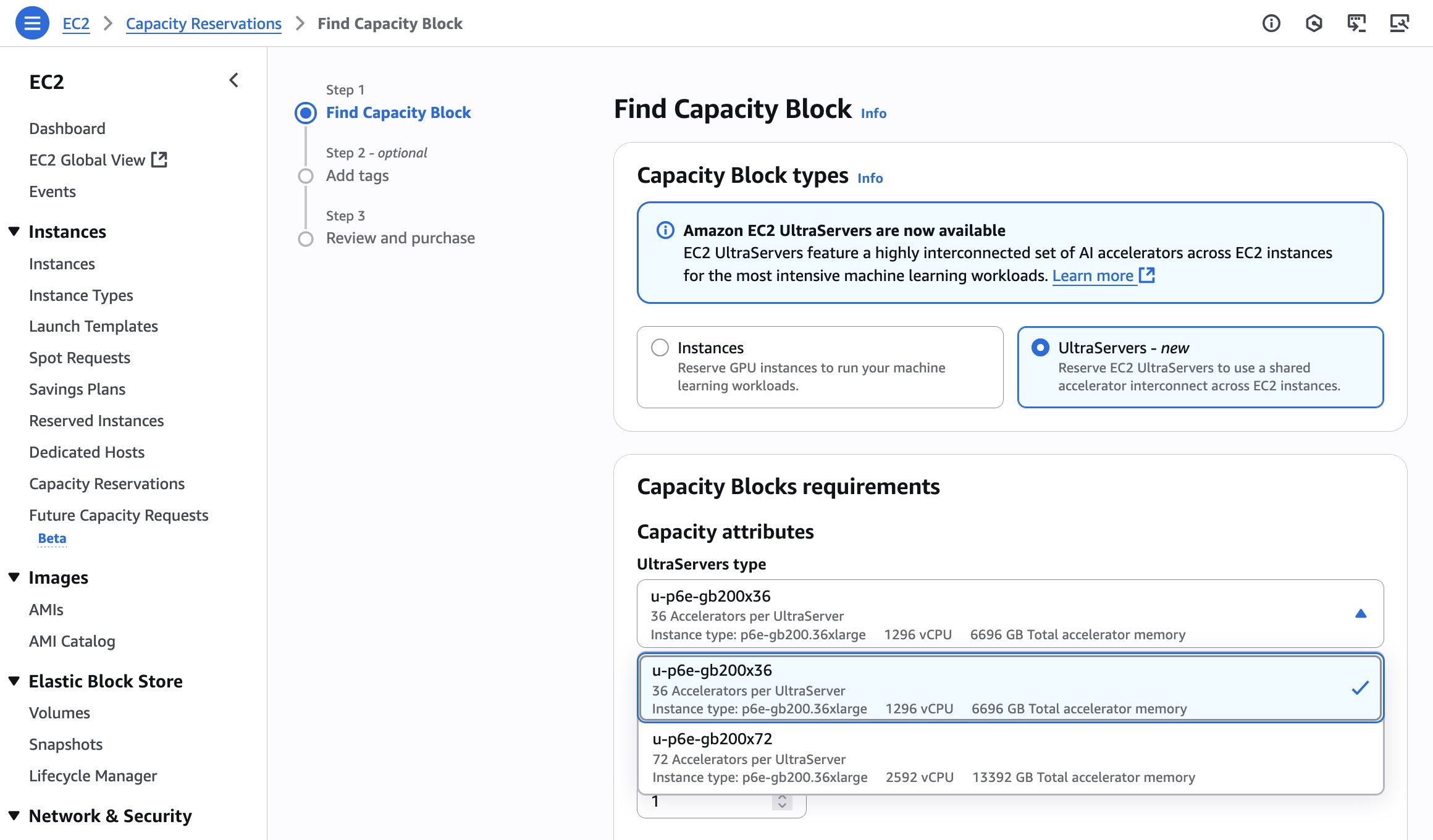
AWS New Amazon EC2 P6e-GB200 UltraServers accelerated by NVIDIA Grace Blackwell GPUs for the highest AI performance 2025-07-10 Read More
Games Girls’ Frontline 2: Exilium – New T-Dolls, Exclusive Rewards, and Anime Expo Surprises Await 2025-07-09 Read More