Games Girls’ Frontline 2: Exilium – New T-Dolls, Exclusive Rewards, and Anime Expo Surprises Await 2025-07-09 Read More
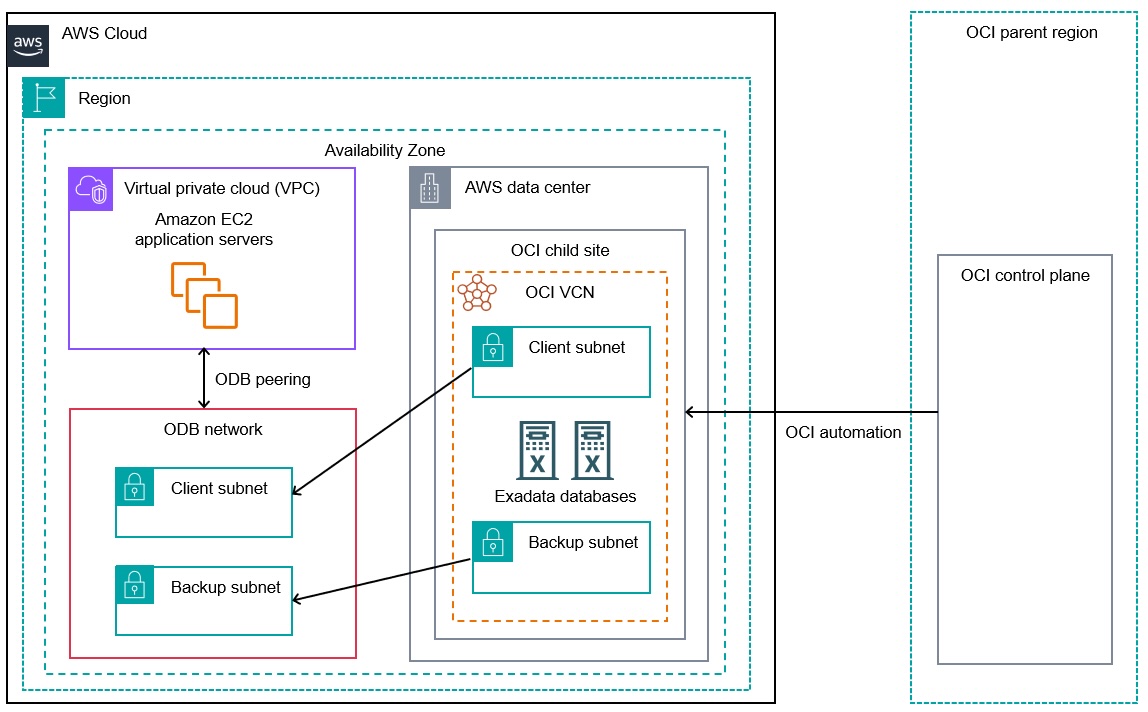
AWS Introducing Oracle Database@AWS for simplified Oracle Exadata migrations to the AWS Cloud 2025-07-08 Read More
AWS AWS Weekly Roundup: Amazon Bedrock API keys, EC2 C8gn instances, Amazon Nova Canvas virtual try-on, and more (July 7, 2025) 2025-07-08 Read More
Games Amazon Prime Members Get 4 More Free Games For Prime Day, Including Star Wars And Marvel Titles 2025-07-08 Read More