Blog and News
Latest Articles
Yet another Cloud Blog
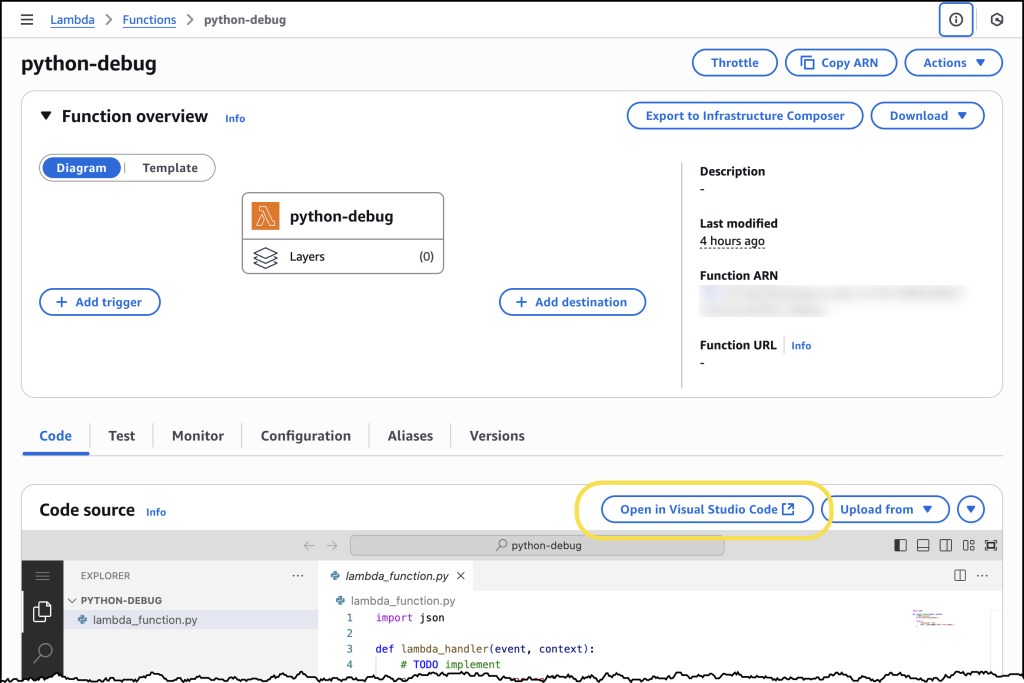

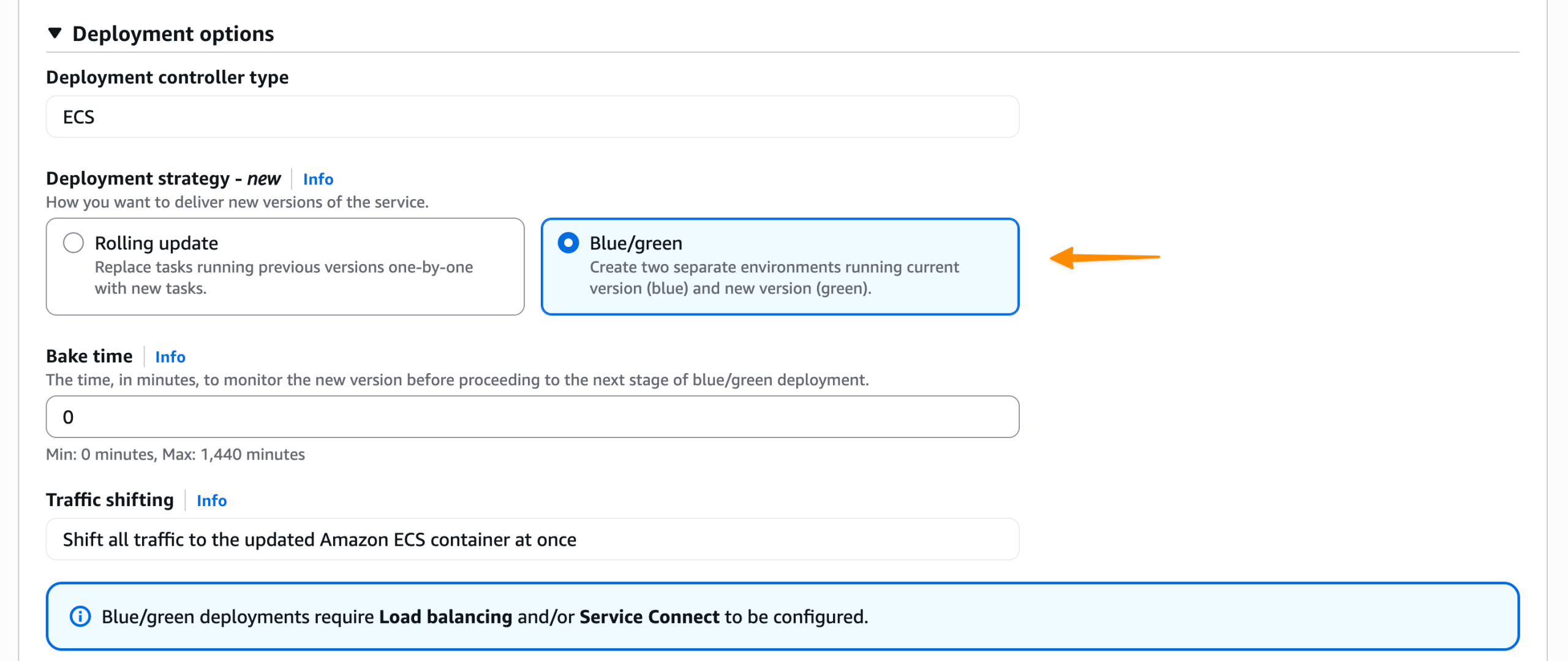

Load more
Yet another Cloud Blog
Senior Cloud Engineer
KenkoGeek Personal Site
Copyright © 2023. All rights reserved.