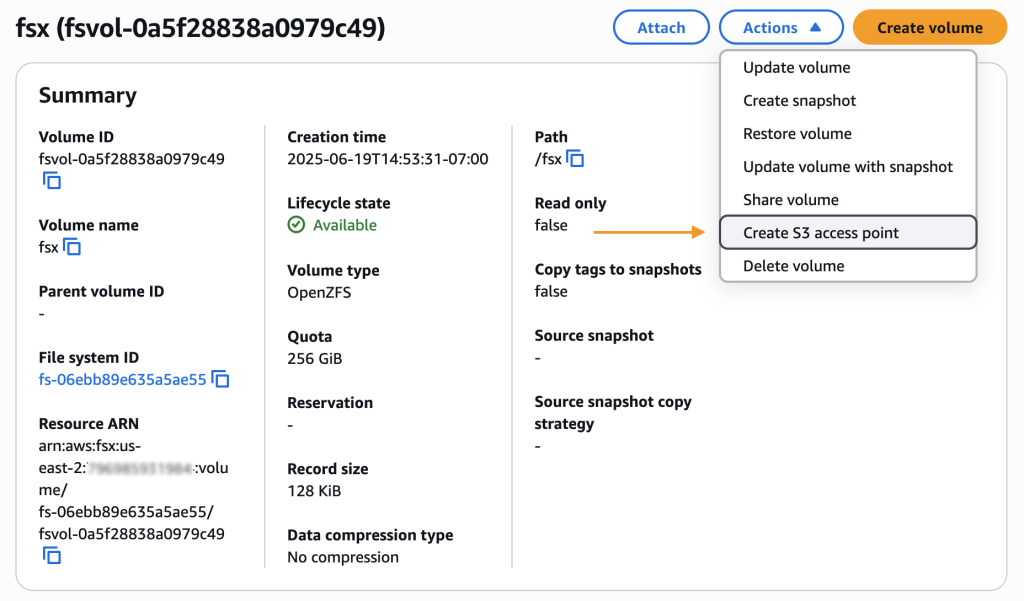
AWS Amazon FSx for OpenZFS now supports Amazon S3 access without any data movement 2025-06-26 Read More
AWS New: Improve Apache Iceberg query performance in Amazon S3 with sort and z-order compaction 2025-06-25 Read More